i wanted to convert a word document to text. So i used a script.
import win32com.client
app = win32com.client.Dispatch('Word.Application')
doc = app.Documents.Open(r'C:\Users\SBYSMR10\Desktop\New folder (2)\GENERAL DATA.doc')
content=doc.Content.Text
app.Quit()
print content
i have the folllowing result:
Now i want to convert this text into a list which contains all its items. I used
content = " ".join(content.replace(u"\xa0", " ").strip().split())
EDIT
When i do that, i get :
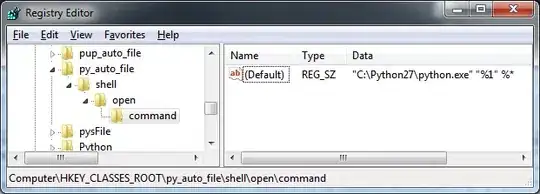
Its not a list. What is the problem? What is that big dot character?