What is the best compression algorithm depends to a large extent on what you are trying to achieve with it, and is dependent on other external variables. Typically, were going to identify and remove spikes, and then remove redundant data. For example;
Known minimum and maximum velocity, acceleration, and ability to tuen will let you remove spikes. If we look at the join distance between a pair of points divided by the time where
velocity = sqrt((xb - xa)^2 + (yb - ya))/(tb-ta)
we can eliminate points where the distance couldn't be travelled in the elapsed time given the speed constraint. We can do the same with acceleration constraints, and change in direction constraints for a given velocity. These constraints change whether the GPS receiver is static, hand held, in a car, in an aeroplane etc...
We can remove redundant points using a moving window looking at three points, where if the an interpolated (x,y,t) for middle point can be compared with an observed point, and the observed point removed if it lies within a specified distance + time tolerance of the interpolated point. We can also curve fit the data and consider the distance to the curve rather than using a moving 3 point window.
The compression may also have differing goals based on the constraints given, e.g. to simply reduce the data size by removing redundant observations and spikes, or to smooth the data as well.
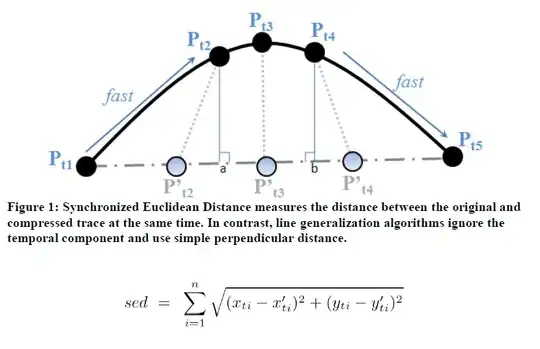
For the former, after checking for spikes based on defined constraints, we simply check the 3d distance of each point to the polyline connecting the compressed points. This is achieved by finding the pair of points before and after the point that has been removed, interpolating a position on the line connecting those points based on the observed time, and comparing the interpolated position with the observed position. The amount of points removed will increase as we allow this distance tolerance to increase.
For the latter we also have to consider how well the smoothed result models the data, the weights imposed by the constraints, and the design shape / curve parameters.
Hope this makes some sense.