at parsing time count how many time it repeated, if it equals to 5, then rename it as another type of token, but how can I do this? Or is there some easy way?
Yes, you can do that with a disambiguating semantic predicate (explanation):
grammar T;
parse
: (short_num | long_num)+ EOF
;
short_num
: {input.LT(1).getText().length() == 5}? NUM
;
long_num
: {input.LT(1).getText().length() == 8}? NUM
;
NUM
: '0'..'9'+
;
SP
: ' ' {skip();}
;
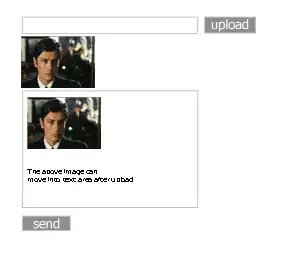
which will parse the input 12345 12345678 as follows:
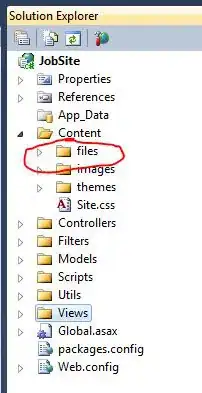
But you can also change the type of the token in the lexer based on some property of the matched text, like this:
grammar T;
parse
: (SHORT | LONG)+ EOF
;
NUM
: '0'..'9'+
{
if(getText().length() == 5) $type = SHORT;
if(getText().length() == 8) $type = LONG;
// when the length is other than 5 or 8, the type of the token will stay NUM
}
;
SP
: ' ' {skip();}
;
fragment SHORT : ;
fragment LONG : ;
which will cause the same input to be parsed like this: