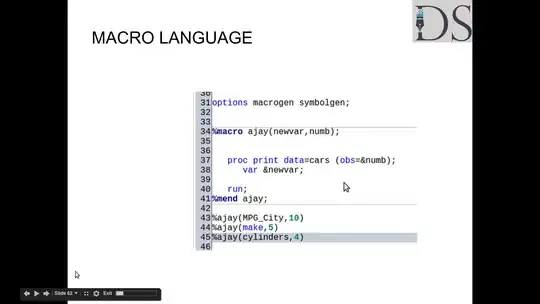
What I want to do is to parse raw natural text and find all the phrases that describe dates.
I've got a fairly big corpus with all the references to dates marked up:
I met him <date>yesterday</date>.
Roger Zelazny was born <date>in 1937</date>
He'll have a hell of a hangover <date>tomorrow morning</date>
I don't want to interpret the date phrases, just locate them. The fact that they're dates is irrelevant (in real life they're not even dates but I don't want to bore you with the details), basically it's just an open-ended set of possible values. The grammar of the values themselves can be approximated as context-free, however it's quite complicated to build manually and with increasing complexity it gets increasingly hard to avoid false positives.
I know this is a bit of a long shot so I'm not expecting an out-of-the-box solution to exist out there, but what technology or research can I potentially use?