I've created an iPhone app that can scan an image of a page of graph paper and can then tell me which squares have been blacked out and which squares are blank.
I do this by scanning from left to right and use the graph paper's lines as guides. When I encounter a graph paper line, I start to look for black, until I hit the graph paper line again. Then, instead of continuing along the scan line, I go ahead and completely scan the square for black. Then I continue on to the next box. At the end of the line, I skip down so many pixels before starting the scan on a new line (since I have already figured out how tall each box is).
This sort of works, but there are problems. Sometimes I mistake the graph lines as "black". Sometimes, if the image is skewed, or I don't have uniform lighting across the page, then I don't get good results.
What I'd like to do is to specify a few "alignment" boxes that I then resize and rotate (and skew) the picture to align with those. Then, I was thinking that once I have the image aligned, I would then know where all the boxes are and won't have to scan for the boxes, just scan inside the location of the boxes to see if they are black. This should be faster and more reliable. And if I were to operate on images coming from the camera, I'd have more flexibility in asking the user to align the picture to match the alignment marks, rather than having to align the image myself.
Given that this is my first Image Processing project, I feel like I am reinventing the wheel. I'd like suggestions on how to do this, and whether to utilize libraries like OpenCV.
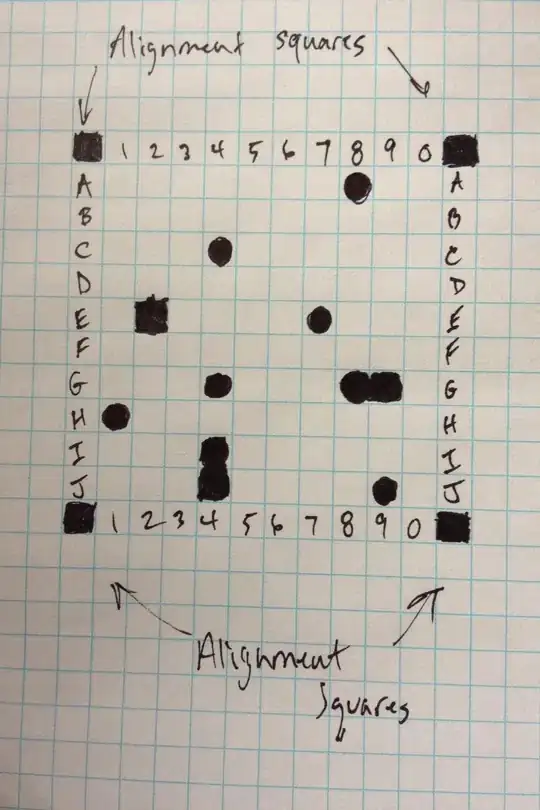
I am enclosing an image similar to what I would like processed. I am looking for a list of all squares that have a significant amount of black marking, i.e. A8, C4, E7, G4, H1, J9.
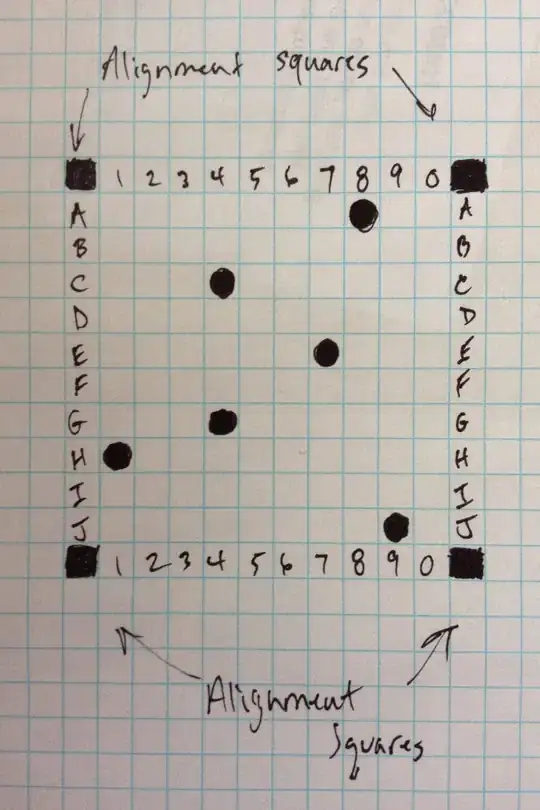
Issues to be aware of:
- Light coverage of the image may not be ideal, but should be relatively consistent across the image (i.e. no shadows)
- All squares may be empty or all dark, and the algorithm needs to be able to determine that
- the image may be skewed or rotated about any of the axis. Rotation about the z axis maybe easy to fix. There may be rotation around the x or y axis making ones side of the image be wider than the other. However, if I scan the image in realtime as it comes from the camera, I can ask the user to align the alignment marks with marks on the screen. How best to ensure that alignment to give the user appropriate feedback? Just checking to make sure that the 4 corners are dark could result in a false positive when the camera is pointing to a black surface.
- not every square will be equally or consistently blacked, but I think there will be enough black to make it unquestionable to a human eye.
- the blue grid may be useful, but there are cases where the black markings may overlap the blue grid. I think a virtual grid is probably better than relying on the printed grid. I would think that using the alignment markers to align the image, would then allow for a precise virtual grid to be laid out. And then the contents of each grid box could be sampled, to see if it was predominantly black, vs scanning from left-to-right, no? Here is another image with more markings on the grid. In this image, in addition to the previous marking in A8, C4, E7, G4, H1, J9, I have marked E2, G8 and G9, and I4 and J4 and you can see how the blue grid is obscured.
- This is my first phase of this project. Eventually I'd like to scale this algorithm to be able to process at least a few hundred slots and possibly different colors.