I am working on a sql server 2008 DB and asp.net mvc web E-commerce app.
I have different users feeding their products to the DB, and I want to compare the prices of products with similar names. I know that string matching is domain specific, but I still need the best generic solution.
What is the most efficient way to group the search results? Should I compare each of the records recursively using the Levenshtien Distance algorithm? Should I do it in the DB, or in the code? Is there a way to implement SSIS Fuzzy Grouping in real time for this task? Is there an efficient way to do it using the Sql server 2008 free text search?
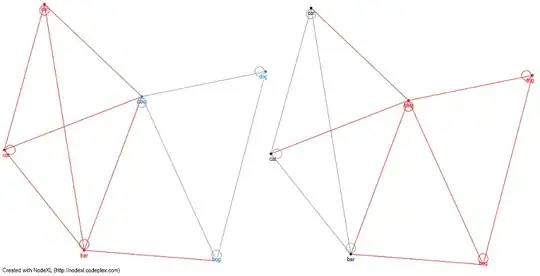
Edit 1: What about network-graph analysis. If I'll define a matrix using the Levenshtien Distance algorithm, I could use a clustering algorithm (for example: clauset newman moore) and seperate groups that don't have phonological path between them. I have attached Nick Johnson (see comment) cat-dog for example (the red lines are the clusters) - and by using the clauset newman moore I am creating 2 different clusters and seperating cats from dogs.
What do you think?