I have done some experiments on achieving concurrent execution on a cluster of 4 Kepler K20c GPUs. I have considered 8 test cases, whose corresponding codes along with the profiler timelines are reported below.
Test case #1 - "Breadth-first" approach - synchronous copy
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices = (double *)malloc(N * sizeof(double));
// --- "Breadth-first" approach - no async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
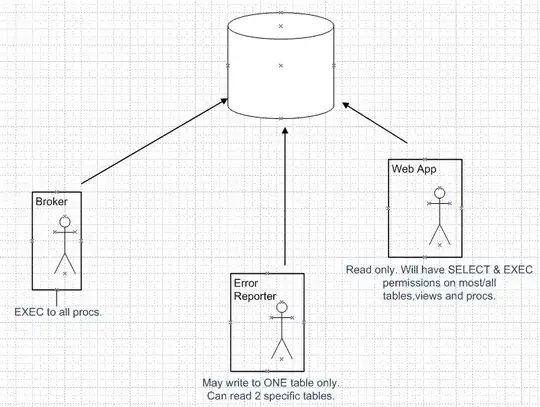
As it can be seen, the use of cudaMemcpy does not enable achieving concurrency in copies, but concurrency is achieved in kernel execution.
Test case #2 - "Depth-first" approach - synchronous copy
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices = (double *)malloc(N * sizeof(double));
// --- "Depth-first" approach - no async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpy(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
This time, concurrency is not achieved neither within memory copies nor within kernel executions.
Test case #3 - "Depth-first" approach - asynchronous copy with streams
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
T *h_data;
cudaStream_t stream;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
gpuErrchk(cudaStreamCreate(&plan.stream));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Depth-first" approach - async
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice, plan[k].stream));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE, 0, plan[k].stream>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost, plan[k].stream));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
Concurrency is achieved, as expected.
Test case #4 - "Depth-first" approach - asynchronous copy within default streams
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
T *h_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Depth-first" approach - no stream
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
Despite using the default stream, concurrency is achieved.
Test case #5 - "Depth-first" approach - asynchronous copy within default stream and unique host cudaMallocHosted vector
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Depth-first" approach - no stream
double *inputMatrices; gpuErrchk(cudaMallocHost(&inputMatrices, N * sizeof(double)));
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
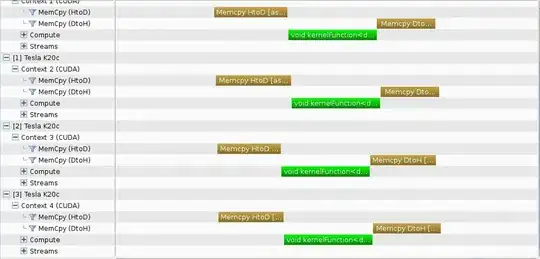
- Profiler timeline -
Concurrency is achieved once again.
Test case #6 - "Breadth-first" approach with asynchronous copy with streams
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
// --- Async
template<class T>
struct plan {
T *d_data;
T *h_data;
cudaStream_t stream;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
gpuErrchk(cudaStreamCreate(&plan.stream));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Breadth-first" approach - async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice, plan[k].stream));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE, 0, plan[k].stream>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost, plan[k].stream));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
Concurrency achieved, as in the corresponding "depth-first" approach.
Test case #7 - "Breadth-first" approach - asynchronous copy within default streams
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
// --- Async
template<class T>
struct plan {
T *d_data;
T *h_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Breadth-first" approach - async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
Concurrency is achieved, as in the corresponding "depth-first" approach.
Test case #8 - "Breadth-first" approach - asynchronous copy within the default stream and unique host cudaMallocHosted vector
- Code -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
// --- Async
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Breadth-first" approach - async
double *inputMatrices; gpuErrchk(cudaMallocHost(&inputMatrices, N * sizeof(double)));
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Profiler timeline -
Concurrency is achieved, as in the corresponding "depth-first" approach.
Conclusion
Using asynchronous copies guarantees concurrent executions, either using purposely created streams or using the default stream.
Note
In all the above examples, I have taken care to provide enough work to do the GPUs, either in terms of copies and of computing tasks. Failing to provide enough work to the cluster may prevent observing concurrent executions.







