An Analogy: Washing Clothes
Imagine a dry cleaning store with the following facilities: a rack for hanging dirty or clean clothes, a washer and a dryer (each of which can wash one garment at a time), a folding table, and an ironing board.
The attendant who does all of the actual washing and drying is rather dim-witted so the store owner, who takes the dry cleaning orders, takes special care to write out each instruction very carefully and explicitly.
On a typical day these instructions may be something along the lines of:
- take the shirt from the rack
- wash the shirt
- dry the shirt
- iron the shirt
- fold the shirt
- put the shirt back on the rack
- take the pants from the rack
- wash the pants
- dry the pants
- fold the pants
- put the pants back on the rack
- take the coat from the rack
- wash the coat
- dry the coat
- iron the coat
- put the coat back on the rack
The attendant follows these instructions to the tee, being very careful not to ever do anything out of order. As you can imagine, it takes a long time to get the day's laundry done because it takes a long time to fully wash, dry, and fold each piece of laundry, and it must all be done one at a time.
However, one day the attendant quits and a new, smarter, attendant is hired who notices that most of the equipment is laying idle at any given time during the day. While the pants were drying neither the ironing board nor the washer were in use. So he decided to make better use of his time. Thus, instead of the above series of steps, he would do this:
- take the shirt from the rack
- wash the shirt, take the pants from the rack
- dry the shirt, wash the pants
- iron the shirt, dry the pants
- fold the shirt, (take the coat from the rack)
- put the shirt back on the rack, fold the pants, (wash the coat)
- put the pants back on the rack, (dry the coat)
- (iron the coat)
- (put the coat back on the rack)
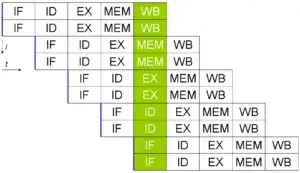
This is pipelining. Sequencing unrelated activities such that they use different components at the same time. By keeping as much of the different components active at once you maximize efficiency and speed up execution time, in this case reducing 16 "cycles" to 9, a speedup of over 40%.
Now, the little dry cleaning shop started to make more money because they could work so much faster, so the owner bought an extra washer, dryer, ironing board, folding station, and even hired another attendant. Now things are even faster, instead of the above, you have:
- take the shirt from the rack, take the pants from the rack
- wash the shirt, wash the pants, (take the coat from the rack)
- dry the shirt, dry the pants, (wash the coat)
- iron the shirt, fold the pants, (dry the coat)
- fold the shirt, put the pants back on the rack, (iron the coat)
- put the shirt back on the rack, (put the coat back on the rack)
This is superscalar design. Multiple sub-components capable of doing the same task simultaneously, but with the processor deciding how to do it. In this case it resulted in a nearly 50% speed boost (in 18 "cycles" the new architecture could run through 3 iterations of this "program" while the previous architecture could only run through 2).
Older processors, such as the 386 or 486, are simple scalar processors, they execute one instruction at a time in exactly the order in which it was received. Modern consumer processors since the PowerPC/Pentium are pipelined and superscalar. A Core2 CPU is capable of running the same code that was compiled for a 486 while still taking advantage of instruction level parallelism because it contains its own internal logic that analyzes machine code and determines how to reorder and run it (what can be run in parallel, what can't, etc.) This is the essence of superscalar design and why it's so practical.
In contrast a vector parallel processor performs operations on several pieces of data at once (a vector). Thus, instead of just adding x and y a vector processor would add, say, x0,x1,x2 to y0,y1,y2 (resulting in z0,z1,z2). The problem with this design is that it is tightly coupled to the specific degree of parallelism of the processor. If you run scalar code on a vector processor (assuming you could) you would see no advantage of the vector parallelization because it needs to be explicitly used, similarly if you wanted to take advantage of a newer vector processor with more parallel processing units (e.g. capable of adding vectors of 12 numbers instead of just 3) you would need to recompile your code. Vector processor designs were popular in the oldest generation of super computers because they were easy to design and there are large classes of problems in science and engineering with a great deal of natural parallelism.
Superscalar processors can also have the ability to perform speculative execution. Rather than leaving processing units idle and waiting for a code path to finish executing before branching a processor can make a best guess and start executing code past the branch before prior code has finished processing. When execution of the prior code catches up to the branch point the processor can then compare the actual branch with the branch guess and either continue on if the guess was correct (already well ahead of where it would have been by just waiting) or it can invalidate the results of the speculative execution and run the code for the correct branch.