Questions are at the end, in bold. But first, let's set up some data:
import numpy as np
import pandas as pd
from itertools import product
np.random.seed(1)
team_names = ['Yankees', 'Mets', 'Dodgers']
jersey_numbers = [35, 71, 84]
game_numbers = [1, 2]
observer_names = ['Bill', 'John', 'Ralph']
observation_types = ['Speed', 'Strength']
row_indices = list(product(team_names, jersey_numbers, game_numbers, observer_names, observation_types))
observation_values = np.random.randn(len(row_indices))
tns, jns, gns, ons, ots = zip(*row_indices)
data = pd.DataFrame({'team': tns, 'jersey': jns, 'game': gns, 'observer': ons, 'obstype': ots, 'value': observation_values})
data = data.set_index(['team', 'jersey', 'game', 'observer', 'obstype'])
data = data.unstack(['observer', 'obstype'])
data.columns = data.columns.droplevel(0)
this gives:
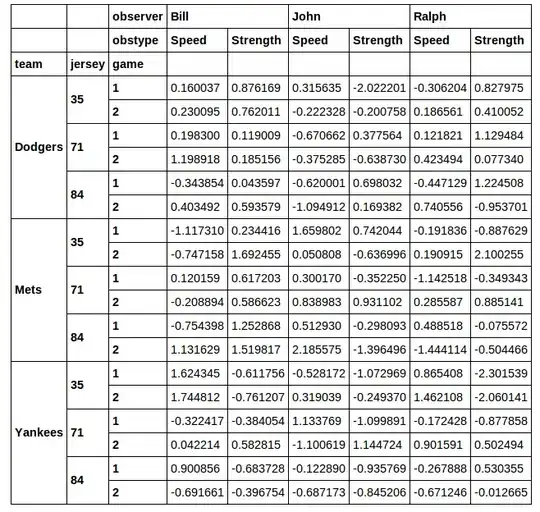
I want to pluck out a subset of this DataFrame for subsequent analysis. Say I wanted to slice out the rows where the jersey number is 71. I don't really like the idea of using xs to do this. When you do a cross section via xs you lose the column you selected on. If I run:
data.xs(71, axis=0, level='jersey')
then I get back the right rows, but I lose the jersey column.
Also, xs doesn't seem like a great solution for the case where I want a few different values from the jersey column. I think a much nicer solution is the one found here:
data[[j in [71, 84] for t, j, g in data.index]]

You could even filter on a combination of jerseys and teams:
data[[j in [71, 84] and t in ['Dodgers', 'Mets'] for t, j, g in data.index]]
Nice!
So the question: how can I do something similar for selecting a subset of columns. For example, say I want only the columns representing data from Ralph. How can I do that without using xs? Or what if I wanted only the columns with observer in ['John', 'Ralph']? Again, I'd really prefer a solution that keeps all the levels of the row and column indices in the result...just like the boolean indexing examples above.
I can do what I want, and even combine selections from both the row and column indices. But the only solution I've found involves some real gymnastics:
data[[j in [71, 84] and t in ['Dodgers', 'Mets'] for t, j, g in data.index]]\
.T[[obs in ['John', 'Ralph'] for obs, obstype in data.columns]].T
And thus the second question: is there a more compact way to do what I just did above?
