It is follow-up question for this MIC question. When adding items to the vector of reference wrappers I spend about 80% of time inside ++ operator whatever iterating approach I choose.
The query works as following
VersionView getVersionData(int subdeliveryGroupId, int retargetingId,
const std::wstring &flightName) const {
VersionView versions;
for (auto i = 0; i < 3; ++i) {
for (auto j = 0; j < 3; ++j) {
versions.insert(m_data.get<mvKey>().equal_range(boost::make_tuple(subdeliveryGroupId + i, retargetingId + j,
flightName)));
}
}
return versions;
}
I've tried following ways to fill the reference wrapper
template <typename InputRange> void insert(const InputRange &rng) {
// 1) base::insert(end(), rng.first, rng.second); // 12ms
// 2) std::copy(rng.first, rng.second, std::back_inserter(*this)); // 6ms
/* 3) size_t start = size(); // 12ms
auto tmp = std::reference_wrapper<const
VersionData>(VersionData(0,0,L""));
resize(start + boost::size(rng), tmp);
auto beg = rng.first;
for (;beg != rng.second; ++beg, ++start)
{
this->operator[](start) = std::reference_wrapper<const VersionData>(*beg);
}
*/
std::copy(rng.first, rng.second, std::back_inserter(*this));
}
Whatever I do I pay for operator ++ or the size method which just increments the iterator - meaning I'm still stuck in ++. So the question is if there is a way to iterate result ranges faster. If there is no such a way is it worth to try and go down the implementation of equal_range adding new argument which holds reference to the container of reference_wrapper which will be filled with results instead of creating range?
EDIT 1: sample code
http://coliru.stacked-crooked.com/a/8b82857d302e4a06/
Due to this bug it will not compile on Coliru
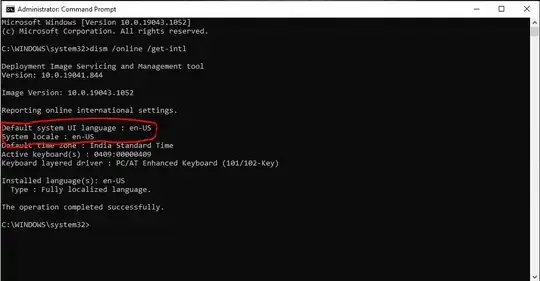
EDIT 2: Call tree, with time spent in operator ++
 EDIT 3: Some concrete stuff. First of all I didnt started this thread just because the operator++ takes too much time in overall execution time and I dont like it just "because" but at this very moment it is the major bottleneck in our performance tests. Each request usually processed in hundreds of microseconds, request similar to this one (they are somewhat more complex) are processed ~1000-1500 micro and it is still acceptable. The original problem was that once the number of items in datastructure grows to hundreds of thousands the performance deteriorates to something like 20 milliseconds. Now after switching to MIC (which drastically improved the code readability, maintainability and overall elegance) I can reach something like 13 milliseconds per request of which 80%-90% spent in operator++. Now the question if this could be improved somehow or should I look for some tar and feathers for me? :)
EDIT 3: Some concrete stuff. First of all I didnt started this thread just because the operator++ takes too much time in overall execution time and I dont like it just "because" but at this very moment it is the major bottleneck in our performance tests. Each request usually processed in hundreds of microseconds, request similar to this one (they are somewhat more complex) are processed ~1000-1500 micro and it is still acceptable. The original problem was that once the number of items in datastructure grows to hundreds of thousands the performance deteriorates to something like 20 milliseconds. Now after switching to MIC (which drastically improved the code readability, maintainability and overall elegance) I can reach something like 13 milliseconds per request of which 80%-90% spent in operator++. Now the question if this could be improved somehow or should I look for some tar and feathers for me? :)