To find out which one is the most efficient solution, we provide a test-script that evaluates the performance. The first plot depicts runtimes for growing length of the vector runLengths, where the entries are uniformly distributed with maximum length 200. A modification of gnovice's solution is the fastest, with Divakar's solution being second place.
This second plot uses nearly the same test data except it includes an initial run of length 2000. This mostly affects both bsxfun solutions, whereas the other solutions will perform quite similarly.
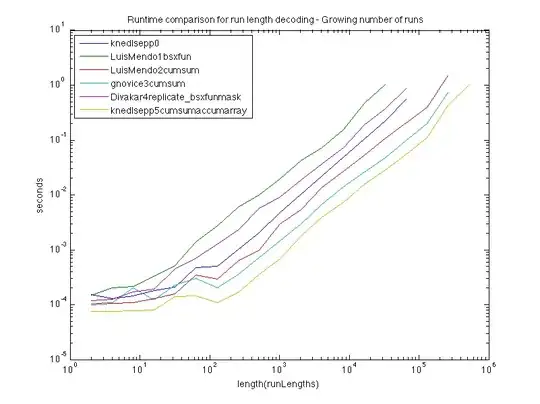
The tests suggest that a modification of gnovice's original answer will be the most performant.
If you want to do the speed comparison yourself, here's the code used to generate the plot above.
function theLastRunLengthDecodingComputationComparisonYoullEverNeed()
Funcs = {@knedlsepp0, ...
@LuisMendo1bsxfun, ...
@LuisMendo2cumsum, ...
@gnovice3cumsum, ...
@Divakar4replicate_bsxfunmask, ...
@knedlsepp5cumsumaccumarray
};
%% Growing number of runs, low maximum sizes in runLengths
ns = 2.^(1:25);
paramGenerators{1} = arrayfun(@(n) @(){randi(200,n,1)}, ns,'uni',0);
paramGenerators{2} = arrayfun(@(n) @(){[2000;randi(200,n,1)]}, ns,'uni',0);
for i = 1:2
times = compareFunctions(Funcs, paramGenerators{i}, 0.5);
finishedComputations = any(~isnan(times),2);
h = figure('Visible', 'off');
loglog(ns(finishedComputations), times(finishedComputations,:));
legend(cellfun(@func2str,Funcs,'uni',0),'Location','NorthWest','Interpreter','none');
title('Runtime comparison for run length decoding - Growing number of runs');
xlabel('length(runLengths)'); ylabel('seconds');
print(['-f',num2str(h)],'-dpng','-r100',['RunLengthComparsion',num2str(i)]);
end
end
function times = compareFunctions(Funcs, paramGenerators, timeLimitInSeconds)
if nargin<3
timeLimitInSeconds = Inf;
end
times = zeros(numel(paramGenerators),numel(Funcs));
for i = 1:numel(paramGenerators)
Params = feval(paramGenerators{i});
for j = 1:numel(Funcs)
if max(times(:,j))<timeLimitInSeconds
times(i,j) = timeit(@()feval(Funcs{j},Params{:}));
else
times(i,j) = NaN;
end
end
end
end
%% // #################################
%% // HERE COME ALL THE FANCY FUNCTIONS
%% // #################################
function V = knedlsepp0(runLengths, values)
[~,V] = histc(1:sum(runLengths), cumsum([1,runLengths(:).']));%'
if nargin>1
V = reshape(values(V), 1, []);
end
V = shiftdim(V, ~isrow(runLengths));
end
%% // #################################
function V = LuisMendo1bsxfun(runLengths, values)
nn = 1:numel(runLengths);
if nargin==1 %// handle one-input case
values = nn;
end
V = values(nonzeros(bsxfun(@times, nn,...
bsxfun(@le, (1:max(runLengths)).', runLengths(:).'))));
if size(runLengths,1)~=size(values,1) %// adjust orientation of output vector
V = V.'; %'
end
end
%% // #################################
function V = LuisMendo2cumsum(runLengths, values)
if nargin==1 %// handle one-input case
values = 1:numel(runLengths);
end
[ii, ~, jj] = find(runLengths(:));
V(cumsum(jj(end:-1:1))) = 1;
V = values(ii(cumsum(V(end:-1:1))));
if size(runLengths,1)~=size(values,1) %// adjust orientation of output vector
V = V.'; %'
end
end
%% // #################################
function V = gnovice3cumsum(runLengths, values)
isColumnVector = size(runLengths,1)>1;
if nargin==1 %// handle one-input case
values = 1:numel(runLengths);
end
values = reshape(values(runLengths~=0),1,[]);
if isempty(values) %// If there are no runs
V = []; return;
end
runLengths = nonzeros(runLengths(:));
index = zeros(1,sum(runLengths));
index(cumsum([1;runLengths(1:end-1)])) = 1;
V = values(cumsum(index));
if isColumnVector %// adjust orientation of output vector
V = V.'; %'
end
end
%% // #################################
function V = Divakar4replicate_bsxfunmask(runLengths, values)
if nargin==1 %// Handle one-input case
values = 1:numel(runLengths);
end
%// Do size checking to make sure that both values and runlengths are row vectors.
if size(values,1) > 1
values = values.'; %//'
end
if size(runLengths,1) > 1
yes_transpose_output = false;
runLengths = runLengths.'; %//'
else
yes_transpose_output = true;
end
maxlen = max(runLengths);
all_values = repmat(values,maxlen,1);
%// OR all_values = values(ones(1,maxlen),:);
V = all_values(bsxfun(@le,(1:maxlen)',runLengths)); %//'
%// Bring the shape of V back to the shape of runlengths
if yes_transpose_output
V = V.'; %//'
end
end
%% // #################################
function V = knedlsepp5cumsumaccumarray(runLengths, values)
isRowVector = size(runLengths,2)>1;
%// Actual computation using column vectors
V = cumsum(accumarray(cumsum([1; runLengths(:)]), 1));
V = V(1:end-1);
%// In case of second argument
if nargin>1
V = reshape(values(V),[],1);
end
%// If original was a row vector, transpose
if isRowVector
V = V.'; %'
end
end