Context
We have 6 instances of Cassandra hosted on AWS, separated into 3 different regions, 2 per regions (2 in eu-west, 2 in us-west, 2 in ap-southeast).
2 days ago, we moved 2 of our EC2 Cassandra instances from us-west-1 to us-east-1. When I say "move" I mean that we decommissioned them and added 2 new instances on our cluster.
We ran nodetool repair which didn't do anything, and nodetool rebuild which synchronized our data from the eu-west data centre. Following that change we noticed that multiple instances on our Cassandra cluster were using over 70% CPU and had incoming traffic.
At first, we thought it was the replication taking place, but considering that we only had 500MB of data, and that it is still running we are puzzled as to what is happening.
Instances hardware:
All of our instances are running on m3.medium which means that we are on:
- 1 CPU, 2.5 GHz
- 3.75 GB of RAM
- 4GB SSD
Also we have mounted an EBS volume for /var/lib/cassandra which is actually a RAID0 of 6 SSDs on EBS:
- EBS volume 300GB SSD, RAID0
Software Version:
Cassandra Version: 2.0.12
Thoughts:
After analysing our data we thought this was caused by Cassandra data compaction.
There is another stackoverflow question around the same subject: Cassandra compaction tasks stuck.
However, this was solved by going for a single SSD (Azure Premium Storage - still in preview) and no RAID0 configured for Cassandra, and as the author said, there is no reason for this to fix the underlying problem (why would removing the RAID0 part from the equation fix this?).
We are not keen yet to move to a local storage as AWS pricing is a lot higher than what we have now. Even though, if it really is the cause of our problem, we will try it.
Another reason why this sounds like a deeper problem is that we have data showing that these EBS volumes have been writing/reading a lot of data in the last 3 days.
Since we moved instances, we get something around 300-400KB of written data per second on each EBS volume, so since we have a RAID0, 6 times this amount per second = 1.8-2.4MB/s. This amounts to ~450GB of data written PER instance over the last 3 days. And we have basically the same value for READ operation too.
We are only running tests on them at the moment, so the only traffic we are getting is coming from our CI server and eventually from the communication that Gossip is doing between the instances.
Debug notes
Output of nodetool status:
Datacenter: cassandra-eu-west-1-A
=================================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN xxx.xxx.xxx.xxx 539.5 MB 256 17.3% 12341234-1234-1234-1234-12341234123412340cd7 eu-west-1c
UN xxx.xxx.xxx.xxx 539.8 MB 256 14.4% 30ff8d00-1ab6-4538-9c67-a49e9ad34672 eu-west-1b
Datacenter: cassandra-ap-southeast-1-A
======================================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN xxx.xxx.xxx.xxx 585.13 MB 256 16.9% a0c45f3f-8479-4046-b3c0-b2dd19f07b87 ap-southeast-1a
UN xxx.xxx.xxx.xxx 588.66 MB 256 17.8% b91c5863-e1e1-4cb6-b9c1-0f24a33b4baf ap-southeast-1b
Datacenter: cassandra-us-east-1-A
=================================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN xxx.xxx.xxx.xxx 545.56 MB 256 15.2% ab049390-f5a1-49a9-bb58-b8402b0d99af us-east-1d
UN xxx.xxx.xxx.xxx 545.53 MB 256 18.3% 39c698ea-2793-4aa0-a28d-c286969febc4 us-east-1e
Output of nodetool compactionstats:
pending tasks: 64
compaction type keyspace table completed total unit progress
Compaction staging stats_hourly 418858165 1295820033 bytes 32.32%
Active compaction remaining time : 0h00m52s
Running dstat on unhealthy instance:
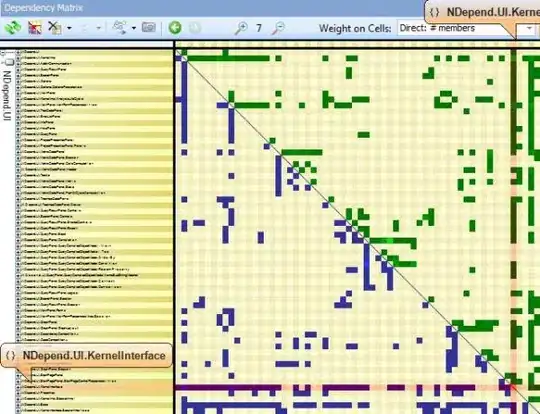
Compaction history in graph form (average of 300 times per hour starting the 16th):
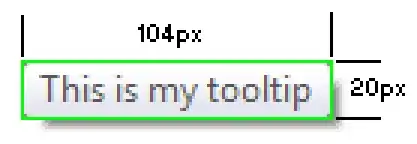
EBS Volumes usage:

Running df -h:
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 33G 11G 21G 34% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
udev 1.9G 12K 1.9G 1% /dev
tmpfs 377M 424K 377M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 1.9G 4.0K 1.9G 1% /run/shm
none 100M 0 100M 0% /run/user
/dev/xvdb 3.9G 8.1M 3.7G 1% /mnt
/dev/md0 300G 2.5G 298G 1% /var/lib/cassandra
Running nodetool tpstats:
Pool Name Active Pending Completed Blocked All time blocked
MutationStage 0 0 3191689 0 0
ReadStage 0 0 574633 0 0
RequestResponseStage 0 0 2698972 0 0
ReadRepairStage 0 0 2721 0 0
ReplicateOnWriteStage 0 0 0 0 0
MiscStage 0 0 62601 0 0
HintedHandoff 0 1 443 0 0
FlushWriter 0 0 88811 0 0
MemoryMeter 0 0 1472 0 0
GossipStage 0 0 979483 0 0
CacheCleanupExecutor 0 0 0 0 0
InternalResponseStage 0 0 25 0 0
CompactionExecutor 1 39 99881 0 0
ValidationExecutor 0 0 62599 0 0
MigrationStage 0 0 40 0 0
commitlog_archiver 0 0 0 0 0
AntiEntropyStage 0 0 149095 0 0
PendingRangeCalculator 0 0 23 0 0
MemtablePostFlusher 0 0 173847 0 0
Message type Dropped
READ 0
RANGE_SLICE 0
_TRACE 0
MUTATION 0
COUNTER_MUTATION 0
BINARY 0
REQUEST_RESPONSE 0
PAGED_RANGE 0
READ_REPAIR 0
Running iptraf, sorted by bytes: