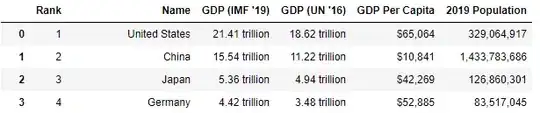
Here is a working example for a generic <table>. (Though not using your page due javascript execution needed to load table data)
Extracting the table data from here GDP (Gross Domestic Product) by countries.
from bs4 import BeautifulSoup as Soup
html = ... # read your html with urllib/requests etc.
soup = BeautifulSoup(html, parser='lxml')
htmltable = soup.find('table', { 'class' : 'table table-striped' })
# where the dictionary specify unique attributes for the 'table' tag
Bellow the function parses a html segment started with tag <table> followed by multiple <tr> (table rows) and inner <td> (table data) tags. It returns a list of rows with inner columns. Accepts only one <th> (table header/data) in the first row.
def tableDataText(table):
"""Parses a html segment started with tag <table> followed
by multiple <tr> (table rows) and inner <td> (table data) tags.
It returns a list of rows with inner columns.
Accepts only one <th> (table header/data) in the first row.
"""
def rowgetDataText(tr, coltag='td'): # td (data) or th (header)
return [td.get_text(strip=True) for td in tr.find_all(coltag)]
rows = []
trs = table.find_all('tr')
headerow = rowgetDataText(trs[0], 'th')
if headerow: # if there is a header row include first
rows.append(headerow)
trs = trs[1:]
for tr in trs: # for every table row
rows.append(rowgetDataText(tr, 'td') ) # data row
return rows
Using it we get (first two rows).
list_table = tableDataText(htmltable)
list_table[:2]
[['Rank',
'Name',
"GDP (IMF '19)",
"GDP (UN '16)",
'GDP Per Capita',
'2019 Population'],
['1',
'United States',
'21.41 trillion',
'18.62 trillion',
'$65,064',
'329,064,917']]
That can be easily transformed in a pandas.DataFrame for more advanced manipulation.
import pandas as pd
dftable = pd.DataFrame(list_table[1:], columns=list_table[0])
dftable.head(4)