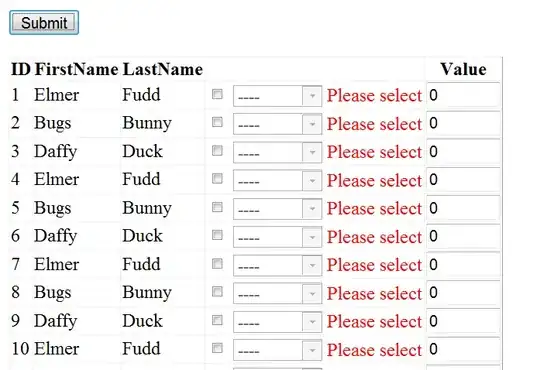
I thought that maybe it might be an option to simply combine your two propositions, while scaling up the differences to make them visible.
What follows is an attempt to do this with ggplot2. Actually it was quite a bit more involved to do this than I initially thought, and I'm definitely not a hundred percent satisfied with the result; but maybe it helps nevertheless. Comments and improvements very welcome.
library(ggplot2)
library(dplyr)
## function that replicates default ggplot2 colors
## taken from [1]
gg_color_hue <- function(n) {
hues = seq(15, 375, length=n+1)
hcl(h=hues, l=65, c=100)[1:n]
}
## Set up sample data
set.seed(1)
n <- 2000
x1 <- rlnorm(n, 0, 1)
x2 <- rlnorm(n, 0, 1.1)
df <- bind_rows(data.frame(sample=1, x=x1), data.frame(sample=2, x=x2)) %>%
mutate(sample = as.factor(sample))
## Calculate density estimates
g1 <- ggplot(df, aes(x=x, group=sample, colour=sample)) +
geom_density(data = df) + xlim(0, 10)
gg1 <- ggplot_build(g1)
## Use these estimates (available at the same x coordinates!) for
## calculating the differences.
## Inspired by [2]
x <- gg1$data[[1]]$x[gg1$data[[1]]$group == 1]
y1 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 1]
y2 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 2]
df2 <- data.frame(x = x, ymin = pmin(y1, y2), ymax = pmax(y1, y2),
side=(y1<y2), ydiff = y2-y1)
g2 <- ggplot(df2) +
geom_ribbon(aes(x = x, ymin = ymin, ymax = ymax, fill = side, alpha = 0.5)) +
geom_line(aes(x = x, y = 5 * abs(ydiff), colour = side)) +
geom_area(aes(x = x, y = 5 * abs(ydiff), fill = side, alpha = 0.4))
g3 <- g2 +
geom_density(data = df, size = 1, aes(x = x, group = sample, colour = sample)) +
xlim(0, 10) +
guides(alpha = FALSE, colour = FALSE) +
ylab("Curves: density\n Shaded area: 5 * difference of densities") +
scale_fill_manual(name = "samples", labels = 1:2, values = gg_color_hue(2)) +
scale_colour_manual(limits = list(1, 2, FALSE, TRUE), values = rep(gg_color_hue(2), 2))
print(g3)

Sources: SO answer 1, SO answer 2
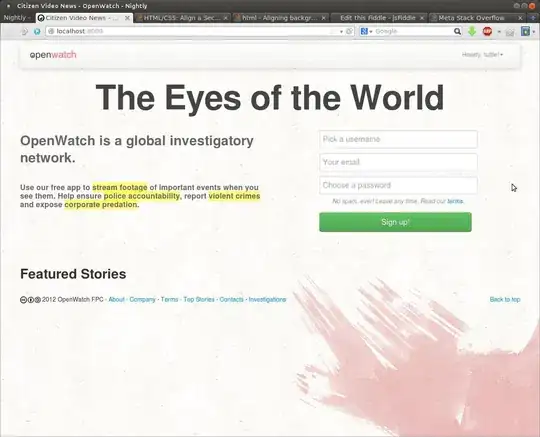
As suggested by @Gregor in the comments, here's a version that does two separate plots below eachother but sharing the same x axis scaling. At least the legends should obviously be tweaked.
library(ggplot2)
library(dplyr)
library(grid)
## function that replicates default ggplot2 colors
## taken from [1]
gg_color_hue <- function(n) {
hues = seq(15, 375, length=n+1)
hcl(h=hues, l=65, c=100)[1:n]
}
## Set up sample data
set.seed(1)
n <- 2000
x1 <- rlnorm(n, 0, 1)
x2 <- rlnorm(n, 0, 1.1)
df <- bind_rows(data.frame(sample=1, x=x1), data.frame(sample=2, x=x2)) %>%
mutate(sample = as.factor(sample))
## Calculate density estimates
g1 <- ggplot(df, aes(x=x, group=sample, colour=sample)) +
geom_density(data = df) + xlim(0, 10)
gg1 <- ggplot_build(g1)
## Use these estimates (available at the same x coordinates!) for
## calculating the differences.
## Inspired by [2]
x <- gg1$data[[1]]$x[gg1$data[[1]]$group == 1]
y1 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 1]
y2 <- gg1$data[[1]]$y[gg1$data[[1]]$group == 2]
df2 <- data.frame(x = x, ymin = pmin(y1, y2), ymax = pmax(y1, y2),
side=(y1<y2), ydiff = y2-y1)
g2 <- ggplot(df2) +
geom_ribbon(aes(x = x, ymin = ymin, ymax = ymax, fill = side, alpha = 0.5)) +
geom_density(data = df, size = 1, aes(x = x, group = sample, colour = sample)) +
xlim(0, 10) +
guides(alpha = FALSE, fill = FALSE)
g3 <- ggplot(df2) +
geom_line(aes(x = x, y = abs(ydiff), colour = side)) +
geom_area(aes(x = x, y = abs(ydiff), fill = side, alpha = 0.4)) +
guides(alpha = FALSE, fill = FALSE)
## See [3]
grid.draw(rbind(ggplotGrob(g2), ggplotGrob(g3), size="last"))
... or with abs(ydiff) replaced by ydiff in the construction of the second plot:
Source: SO answer 3