The following, when copied and pasted directly into R works fine:
> character_test <- function() print("R同时也被称为GNU S是一个强烈的功能性语言和环境,探索统计数据集,使许多从自定义数据图形显示...")
> character_test()
[1] "R同时也被称为GNU S是一个强烈的功能性语言和环境,探索统计数据集,使许多从自定义数据图形显示..."
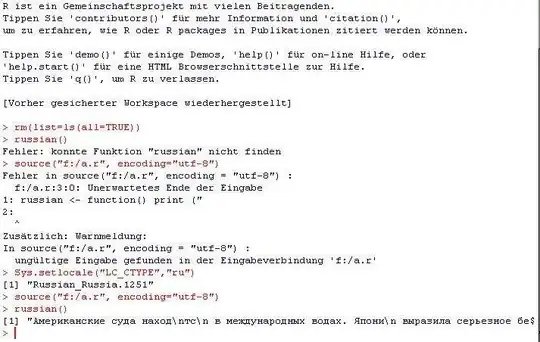
However, if I make a file called character_test.R containing the EXACT SAME code, save it in UTF-8 encoding (so as to retain the special Chinese characters), then when I source() it in R, I get the following error:
> source(file="C:\\Users\\Tony\\Desktop\\character_test.R", encoding = "UTF-8")
Error in source(file = "C:\\Users\\Tony\\Desktop\\character_test.R", encoding = "utf-8") :
C:\Users\Tony\Desktop\character_test.R:3:0: unexpected end of input
1: character.test <- function() print("R
2:
^
In addition: Warning message:
In source(file = "C:\\Users\\Tony\\Desktop\\character_test.R", encoding = "UTF-8") :
invalid input found on input connection 'C:\Users\Tony\Desktop\character_test.R'
Any help you can offer in solving and helping me to understand what is going on here would be much appreciated.
> sessionInfo() # Windows 7 Pro x64
R version 2.12.1 (2010-12-16)
Platform: x86_64-pc-mingw32/x64 (64-bit)
locale:
[1] LC_COLLATE=English_United Kingdom.1252
[2] LC_CTYPE=English_United Kingdom.1252
[3] LC_MONETARY=English_United Kingdom.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United Kingdom.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
loaded via a namespace (and not attached):
[1] tools_2.12.1
and
> l10n_info()
$MBCS
[1] FALSE
$`UTF-8`
[1] FALSE
$`Latin-1`
[1] TRUE
$codepage
[1] 1252