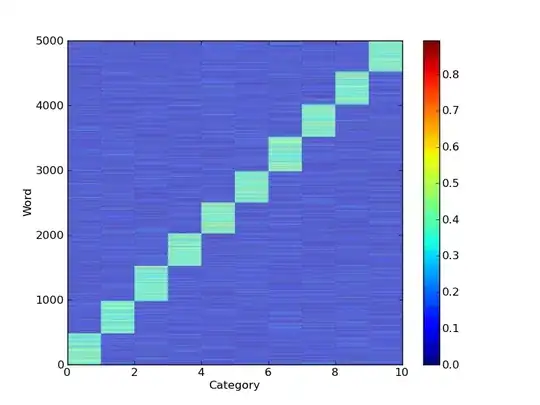
I have a very large matrix(10x55678) in "numpy" matrix format. the rows of this matrix correspond to some "topics" and the columns correspond to words(unique words from a text corpus). Each entry i,j in this matrix is a probability, meaning that word j belongs to topic i with probability x. since I am using ids rather than the real words and since the dimension of my matrix is really large I need to visualized it in a way.Which visualization do you suggest? a simple plot? or a more sophisticated and informative one?(i am asking these cause I am ignorant about the useful types of visualization). If possible can you give me an example that using a numpy matrix? thanks
the reason I asked this question is that I want to have a general view of the word-topic distributions in my corpus. any other methods are welcome