I am applying transfer-learning on a pre-trained network using the GPU version of keras. I don't understand how to define the parameters max_queue_size, workers, and use_multiprocessing. If I change these parameters (primarily to speed-up learning), I am unsure whether all data is still seen per epoch.
max_queue_size:
maximum size of the internal training queue which is used to "precache" samples from the generator
Question: Does this refer to how many batches are prepared on CPU? How is it related to
workers? How to define it optimally?
workers:
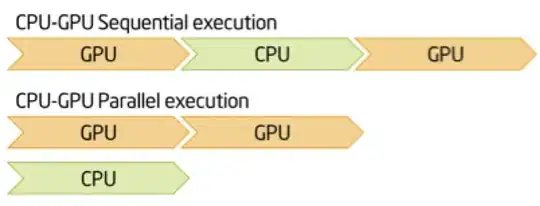
number of threads generating batches in parallel. Batches are computed in parallel on the CPU and passed on the fly onto the GPU for neural network computations
Question: How do I find out how many batches my CPU can/should generate in parallel?
use_multiprocessing:
whether to use process-based threading
Question: Do I have to set this parameter to true if I change
workers? Does it relate to CPU usage?
Related questions can be found here:
- Detailed explanation of model.fit_generator() parameters: queue size, workers and use_multiprocessing
What is the parameter “max_q_size” used for in “model.fit_generator”?
A detailed example of how to use data generators with Keras.
I am using fit_generator() as follows:
history = model.fit_generator(generator=trainGenerator,
steps_per_epoch=trainGenerator.samples//nBatches, # total number of steps (batches of samples)
epochs=nEpochs, # number of epochs to train the model
verbose=2, # verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch
callbacks=callback, # keras.callbacks.Callback instances to apply during training
validation_data=valGenerator, # generator or tuple on which to evaluate the loss and any model metrics at the end of each epoch
validation_steps=
valGenerator.samples//nBatches, # number of steps (batches of samples) to yield from validation_data generator before stopping at the end of every epoch
class_weight=classWeights, # optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function
max_queue_size=10, # maximum size for the generator queue
workers=1, # maximum number of processes to spin up when using process-based threading
use_multiprocessing=False, # whether to use process-based threading
shuffle=True, # whether to shuffle the order of the batches at the beginning of each epoch
initial_epoch=0)
The specs of my machine are:
CPU : 2xXeon E5-2260 2.6 GHz
Cores: 10
Graphic card: Titan X, Maxwell, GM200
RAM: 128 GB
HDD: 4TB
SSD: 512 GB