I am trying to automate number groupings of several lists by exporting the data to ms excel using openpyxl. The output is a list of lists with two sets of numbers per element, the first set being the matched number (0 to 99), and the second is the index number where they matched.
def variable_str_to_list_pairs_overlapping (str):
return [''.join(pair) for pair in zip(str[:-1], str[1:])]
list1 = variable_str_to_list_pairs_overlapping (list1)
list2 = variable_str_to_list_pairs_overlapping (list2)
lst_result = []
for i in range(len(list2)):
if list1[i] == list2[i]:
data = [list1[i], i]
data[0] = int(list1[i])
lst_result.append(data)
print(lst_result)
Output:
[[7, 265], [8, 281], [2, 303], [8, 332], [7, 450], [1, 544], [0,
737], [9, 805], [2, 970], [4, 1103], [4, 1145], [8, 1303], [1,
1575], [4, 1592], [2, 1593], [3, 1948], [4, 2200], [5, 2419], [3,
2464], [9, 2477], [1, 2529], [6, 2785], [2, 2842], [8, 2843], [7,
2930], [3, 2991], [8, 3096], [3, 3248], [2, 3437], [7, 3438], [8,
3511], [0, 3522], [0, 3523], [5, 3590], [6, 3621], [1, 3622], [2,
3671], [6, 3835], [7, 3876]]
I'm looking to export the data to excel in such a way that the first element is assigned as the row index and the second as the value inside the cell
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
dest_filename = 'openpyxltest.xlsx'
for x in lst_result:
ws.cell(row = x[0] + 1, column = +2).value = x[1]
wb.save(filename = dest_filename)
Actual Output:
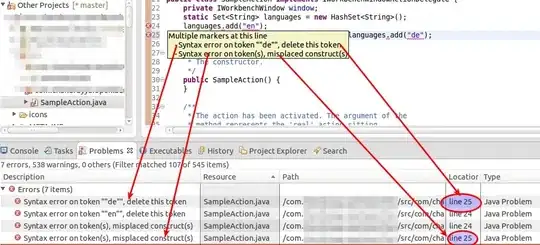
Desired Output:
What do I need to change in my code? Thank you in advance for the help. you guys are awesome! :)
