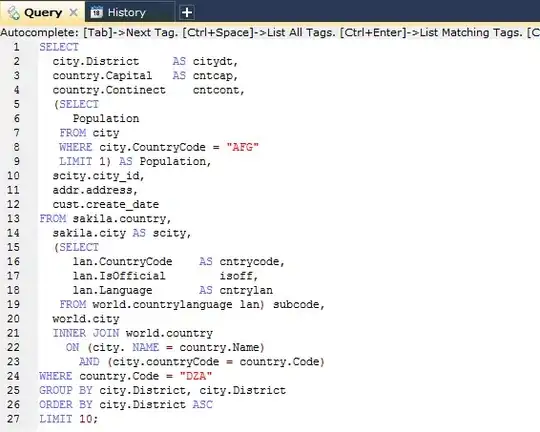
Ok, you need to use Resample.
Let's use your data
content = """0 2020-08-15 16:34:15.838169 False
1 2020-08-17 14:25:08.778913 True
2 2020-08-19 07:44:07.514456 False
3 2020-08-19 14:48:29.160890 True
4 2020-08-20 03:26:00.479444 False
5 2020-08-20 10:57:52.904366 False
6 2020-08-20 19:17:45.079390 True
7 2020-08-20 23:38:41.369156 False
8 2020-08-21 12:21:54.340702 True
9 2020-08-24 19:42:13.458472 False
10 2020-08-24 23:09:39.369394 True
11 2020-08-25 16:35:05.059722 False
12 2020-08-26 01:31:29.243435 True
13 2020-08-26 03:28:25.418322 True
14 2020-08-27 12:42:43.905486 True
15 2020-08-31 10:35:57.143843 False
16 2020-09-02 11:32:54.219081 True
17 2020-09-02 14:07:05.544261 False
18 2020-09-03 08:05:32.133082 False
19 2020-09-10 15:28:46.725916 True
20 2020-09-12 00:57:58.558055 True
21 2020-09-13 21:28:02.450837 True
"""
from io import StringIO
df = pd.read_csv(StringIO(content), sep=" ", header=None, index_col=0)
print(df)
1 2
0
0 2020-08-15 16:34:15.838169 False
1 2020-08-17 14:25:08.778913 True
2 2020-08-19 07:44:07.514456 False
3 2020-08-19 14:48:29.160890 True
4 2020-08-20 03:26:00.479444 False
5 2020-08-20 10:57:52.904366 False
6 2020-08-20 19:17:45.079390 True
7 2020-08-20 23:38:41.369156 False
8 2020-08-21 12:21:54.340702 True
9 2020-08-24 19:42:13.458472 False
10 2020-08-24 23:09:39.369394 True
11 2020-08-25 16:35:05.059722 False
12 2020-08-26 01:31:29.243435 True
13 2020-08-26 03:28:25.418322 True
14 2020-08-27 12:42:43.905486 True
15 2020-08-31 10:35:57.143843 False
16 2020-09-02 11:32:54.219081 True
17 2020-09-02 14:07:05.544261 False
18 2020-09-03 08:05:32.133082 False
19 2020-09-10 15:28:46.725916 True
20 2020-09-12 00:57:58.558055 True
21 2020-09-13 21:28:02.450837 True
Use the first column like index, and then drop it:
df = df.set_index(pd.DatetimeIndex(df.iloc[:,0]))
df.drop(df.columns[0], 1, inplace=True)
df
2
1
2020-08-15 16:34:15.838169 False
2020-08-17 14:25:08.778913 True
2020-08-19 07:44:07.514456 False
2020-08-19 14:48:29.160890 True
2020-08-20 03:26:00.479444 False
2020-08-20 10:57:52.904366 False
2020-08-20 19:17:45.079390 True
2020-08-20 23:38:41.369156 False
2020-08-21 12:21:54.340702 True
2020-08-24 19:42:13.458472 False
2020-08-24 23:09:39.369394 True
2020-08-25 16:35:05.059722 False
2020-08-26 01:31:29.243435 True
2020-08-26 03:28:25.418322 True
2020-08-27 12:42:43.905486 True
2020-08-31 10:35:57.143843 False
2020-09-02 11:32:54.219081 True
2020-09-02 14:07:05.544261 False
2020-09-03 08:05:32.133082 False
2020-09-10 15:28:46.725916 True
2020-09-12 00:57:58.558055 True
2020-09-13 21:28:02.450837 True
Resample by, for example, day, sum, and plot
df.resample('D').sum().plot()
Note that is usefull if you have columns names:
content = """Date Condition
0 2020-08-15 16:34:15.838169 False
1 2020-08-17 14:25:08.778913 True
2 2020-08-19 07:44:07.514456 False
3 2020-08-19 14:48:29.160890 True
4 2020-08-20 03:26:00.479444 False
5 2020-08-20 10:57:52.904366 False
6 2020-08-20 19:17:45.079390 True
7 2020-08-20 23:38:41.369156 False
8 2020-08-21 12:21:54.340702 True
9 2020-08-24 19:42:13.458472 False
10 2020-08-24 23:09:39.369394 True
11 2020-08-25 16:35:05.059722 False
12 2020-08-26 01:31:29.243435 True
13 2020-08-26 03:28:25.418322 True
14 2020-08-27 12:42:43.905486 True
15 2020-08-31 10:35:57.143843 False
16 2020-09-02 11:32:54.219081 True
17 2020-09-02 14:07:05.544261 False
18 2020-09-03 08:05:32.133082 False
19 2020-09-10 15:28:46.725916 True
20 2020-09-12 00:57:58.558055 True
21 2020-09-13 21:28:02.450837 True
"""
from io import StringIO
df = pd.read_csv(StringIO(content), sep=" ", index_col=0)
print(df)
Date Condition
0 2020-08-15 16:34:15.838169 False
1 2020-08-17 14:25:08.778913 True
2 2020-08-19 07:44:07.514456 False
3 2020-08-19 14:48:29.160890 True
4 2020-08-20 03:26:00.479444 False
5 2020-08-20 10:57:52.904366 False
6 2020-08-20 19:17:45.079390 True
7 2020-08-20 23:38:41.369156 False
8 2020-08-21 12:21:54.340702 True
9 2020-08-24 19:42:13.458472 False
10 2020-08-24 23:09:39.369394 True
11 2020-08-25 16:35:05.059722 False
12 2020-08-26 01:31:29.243435 True
13 2020-08-26 03:28:25.418322 True
14 2020-08-27 12:42:43.905486 True
15 2020-08-31 10:35:57.143843 False
16 2020-09-02 11:32:54.219081 True
17 2020-09-02 14:07:05.544261 False
18 2020-09-03 08:05:32.133082 False
19 2020-09-10 15:28:46.725916 True
20 2020-09-12 00:57:58.558055 True
21 2020-09-13 21:28:02.450837 True
and
df = df.set_index(pd.DatetimeIndex(df['Date']))
df.drop(["Date"], 1, inplace=True)
df
Condition
Date
2020-08-15 16:34:15.838169 False
2020-08-17 14:25:08.778913 True
2020-08-19 07:44:07.514456 False
2020-08-19 14:48:29.160890 True
2020-08-20 03:26:00.479444 False
2020-08-20 10:57:52.904366 False
2020-08-20 19:17:45.079390 True
2020-08-20 23:38:41.369156 False
2020-08-21 12:21:54.340702 True
2020-08-24 19:42:13.458472 False
2020-08-24 23:09:39.369394 True
2020-08-25 16:35:05.059722 False
2020-08-26 01:31:29.243435 True
2020-08-26 03:28:25.418322 True
2020-08-27 12:42:43.905486 True
2020-08-31 10:35:57.143843 False
2020-09-02 11:32:54.219081 True
2020-09-02 14:07:05.544261 False
2020-09-03 08:05:32.133082 False
2020-09-10 15:28:46.725916 True
2020-09-12 00:57:58.558055 True
2020-09-13 21:28:02.450837 True
df.resample('D').sum().plot()