I have an issue with plotting the big CSV file with Y-axis values ranging from 1 upto 20+ millions. There are two problems I am facing right now.
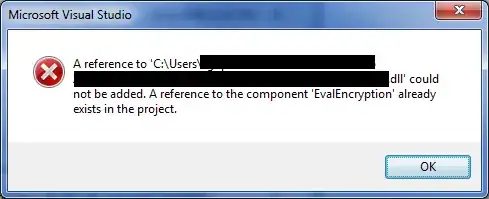
The Y-axis do not show all the values that it is suppose to. When using the original data, it shows upto 6 million, instead of showing all the data upto 20 millions. In the sample data (smaller data) I put below, it only shows the first Y-axis value and does not show any other values.
In the label section, since I am using hue and style = name, "name" appears as the label title and as an item inside.
Questions:
Could anyone give me a sample or help me to answer how may I show all the Y-axis values? How can I fix it so all the Y-values show up?
How can I get rid of "name" under label section without getting rid of shapes and colors for the scatter points?
(Please let me know of any sources exist or this question was answered on some other post without labeling it duplicated. Please also let me know if I have any grammar/spelling issues that I need to fix. Thank you!)
Below you can find the function I am using to plot the graph and the sample data.
def test_graph (file_name):
data_file = pd.read_csv(file_name, header=None, error_bad_lines=False, delimiter="|", index_col = False, dtype='unicode')
data_file.rename(columns={0: 'name',
1: 'date',
2: 'name3',
3: 'name4',
4: 'name5',
5: 'ID',
6: 'counter'}, inplace=True)
data_file.date = pd.to_datetime(data_file['date'], unit='s')
norm = plt.Normalize(1,4)
cmap = plt.cm.tab10
df = pd.DataFrame(data_file)
# Below creates and returns a dictionary of category-point combinations,
# by cycling over the marker points specified.
points = ['o', 'v', '^', '<', '>', '8', 's', 'p', 'H', 'D', 'd', 'P', 'X']
mult = len(df['name']) // len(points) + (len(df['name']) % len(points) > 0)
markers = {key:value for (key, value)
in zip(df['name'], points * mult)} ; markers
sc = sns.scatterplot(data = df, x=df['date'], y=df['counter'], hue = df['name'], style = df['name'], markers = markers, s=50)
ax.set_autoscaley_on(True)
ax.set_title("TEST", size = 12, zorder=0)
plt.legend(title="Names", loc='center left', shadow=True, edgecolor = 'grey', handletextpad = 0.1, bbox_to_anchor=(1, 0.5))
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(100))
plt.xlabel("Dates", fontsize = 12, labelpad = 7)
plt.ylabel("Counter", fontsize = 12)
plt.grid(axis='y', color='0.95')
fig.autofmt_xdate(rotation = 30)
fig = plt.figure(figsize=(20,15),dpi=100)
ax = fig.add_subplot(1,1,1)
test_graph(file_name)
plt.savefig(graph_results + "/Test.png", dpi=100)
# Prevents to cut-off the bottom labels (manually) => makes the bottom part bigger
plt.gcf().subplots_adjust(bottom=0.15)
plt.show()
Sample data
namet1|1582334815|ai1|ai1||150|101
namet1|1582392415|ai2|ai2||142|105
namet2|1582882105|pc1|pc1||1|106
namet2|1582594106|pc1|pc1||1|123
namet2|1580592505|pc1|pc1||1|141
namet2|1580909305|pc1|pc1||1|144
namet3|1581974872|ai3|ai3||140|169
namet1|1581211616|ai4|ai4||134|173
namet2|1582550907|pc1|pc1||1|179
namet2|1582608505|pc1|pc1||1|185
namet4|1581355640|ai5|ai5|bcu|180|298466
namet4|1582651641|pc2|pc2||233|298670
namet5|1582406860|ai6|ai6|bcu|179|298977
namet5|1580563661|pc2|pc2||233|299406
namet6|1581283626|qe1|q0/1|Link to btse1/3|51|299990
namet7|1581643672|ai5|ai5|bcu|180|300046
namet4|1581758842|ai6|ai6|bcu|179|300061
namet6|1581298027|qe2|q0/2|Link to btse|52|300064
namet1|1582680415|pc2|pc2||233|300461
namet6|1581744427|pc3|p90|Link to btsi3a4|55|6215663
namet6|1581730026|pc3|p90|Link to btsi3a4|55|6573348
namet6|1582190826|qe2|q0/2|Link to btse|52|6706378
namet6|1582190826|qe1|q0/1|Link to btse1/3|51|6788568
namet1|1581974815|pc2|pc2||233|6895836
namet4|1581974841|pc2|pc2||233|7874504
namet6|1582176427|qe1|q0/1|Link to btse1/3|51|9497687
namet6|1582176427|qe2|q0/2|Link to btse|52|9529133
namet7|1581974872|pc2|pc2||233|9573450
namet6|1582162027|pc3|p90|Link to btsi3a4|55|9819491
namet6|1582190826|pc3|p90|Link to btsi3a4|55|13494946
namet6|1582176427|pc3|p90|Link to btsi3a4|55|19026820
Results I am getting:
Big data:
Small data:
Updated Graph Updated-graph

{kind=link}