When you create an index on a column or number of columns in MS SQL Server (I'm using version 2005), you can specify that the index on each column be either ascending or descending. I'm having a hard time understanding why this choice is even here. Using binary sort techniques, wouldn't a lookup be just as fast either way? What difference does it make which order I choose?
Asked
Active
Viewed 1e+01k times
3 Answers
159
This primarily matters when used with composite indexes:
CREATE INDEX ix_index ON mytable (col1, col2 DESC);
can be used for either:
SELECT *
FROM mytable
ORDER BY
col1, col2 DESC
or:
SELECT *
FROM mytable
ORDER BY
col1 DESC, col2
, but not for:
SELECT *
FROM mytable
ORDER BY
col1, col2
An index on a single column can be efficiently used for sorting in both ways.
See the article in my blog for details:
Update:
In fact, this can matter even for a single column index, though it's not so obvious.
Imagine an index on a column of a clustered table:
CREATE TABLE mytable (
pk INT NOT NULL PRIMARY KEY,
col1 INT NOT NULL
)
CREATE INDEX ix_mytable_col1 ON mytable (col1)
The index on col1 keeps ordered values of col1 along with the references to rows.
Since the table is clustered, the references to rows are actually the values of the pk. They are also ordered within each value of col1.
This means that that leaves of the index are actually ordered on (col1, pk), and this query:
SELECT col1, pk
FROM mytable
ORDER BY
col1, pk
needs no sorting.
If we create the index as following:
CREATE INDEX ix_mytable_col1_desc ON mytable (col1 DESC)
, then the values of col1 will be sorted descending, but the values of pk within each value of col1 will be sorted ascending.
This means that the following query:
SELECT col1, pk
FROM mytable
ORDER BY
col1, pk DESC
can be served by ix_mytable_col1_desc but not by ix_mytable_col1.
In other words, the columns that constitute a CLUSTERED INDEX on any table are always the trailing columns of any other index on that table.
Quassnoi
- 413,100
- 91
- 616
- 614
-
1When you say "not for..." do you mean it wont work or the performance will be horrible? – Neil N Apr 20 '09 at 19:23
-
5I mean that the index will not be used for the query. The query itself will work, of course, but performance will be poor. – Quassnoi Apr 20 '09 at 20:30
-
`DESC` could speed up Fragmentation on Sequential Data. You should Sort any way you like **without** a New Index for **every** possibility. Sure, you _might_ save milliseconds on a Sort, but is it perceivable to the User? Is it worth all the Additional Disc Space and IO of the new For-Sort-Only Indexes? Is it worth the Overhead you Add to **Every** Insert/Update/Delete? Is it worth Larger & Slower Backups? Backups ALWAYS include Indexes too! My Rule of Thumb: Use 1-Column Indexes for all Common-Filters and Only add Multi-Column Indexes for Commonly-Grouped-Filters and Composite-FK's. – MikeTeeVee Aug 01 '22 at 19:50
-
@MikeTeeVee: I have a feeling that you are posing all these questions as rhetorical, but they are not. "Is it worth" is a very good question to ask, and in a lot of cases the answer is "yes, it totally is". – Quassnoi Aug 01 '22 at 20:16
81
For a true single column index it makes little difference from the Query Optimiser's point of view.
For the table definition
CREATE TABLE T1( [ID] [int] IDENTITY NOT NULL,
[Filler] [char](8000) NULL,
PRIMARY KEY CLUSTERED ([ID] ASC))
The Query
SELECT TOP 10 *
FROM T1
ORDER BY ID DESC
Uses an ordered scan with scan direction BACKWARD as can be seen in the Execution Plan. There is a slight difference however in that currently only FORWARD scans can be parallelised.
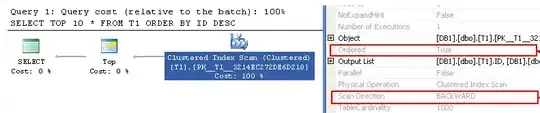
However it can make a big difference in terms of logical fragmentation. If the index is created with keys descending but new rows are appended with ascending key values then you can end up with every page out of logical order. This can severely impact the size of the IO reads when scanning the table and it is not in cache.
See the fragmentation results
avg_fragmentation avg_fragment
name page_count _in_percent fragment_count _size_in_pages
------ ------------ ------------------- ---------------- ---------------
T1 1000 0.4 5 200
T2 1000 99.9 1000 1
for the script below
/*Uses T1 definition from above*/
SET NOCOUNT ON;
CREATE TABLE T2( [ID] [int] IDENTITY NOT NULL,
[Filler] [char](8000) NULL,
PRIMARY KEY CLUSTERED ([ID] DESC))
BEGIN TRAN
GO
INSERT INTO T1 DEFAULT VALUES
GO 1000
INSERT INTO T2 DEFAULT VALUES
GO 1000
COMMIT
SELECT object_name(object_id) AS name,
page_count,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages
FROM
sys.dm_db_index_physical_stats(db_id(), object_id('T1'), 1, NULL, 'DETAILED')
WHERE index_level = 0
UNION ALL
SELECT object_name(object_id) AS name,
page_count,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages
FROM
sys.dm_db_index_physical_stats(db_id(), object_id('T2'), 1, NULL, 'DETAILED')
WHERE index_level = 0
It's possible to use the spatial results tab to verify the supposition that this is because the later pages have ascending key values in both cases.
SELECT page_id,
[ID],
geometry::Point(page_id, [ID], 0).STBuffer(4)
FROM T1
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
UNION ALL
SELECT page_id,
[ID],
geometry::Point(page_id, [ID], 0).STBuffer(4)
FROM T2
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
Martin Smith
- 438,706
- 87
- 741
- 845
-
Thank you Martin for this great TIP,this really helped me in rank queries – TheGameiswar Oct 10 '15 at 05:09
-
I wonder if I have a descending index, then select mycolumn from mytable where indexed_column = \@myvalue is faster when \@myvalue is closer to the maximum possible value than in the case when \@myvalue is closed to the minimum possible value. – Lajos Arpad Oct 24 '16 at 18:15
-
@LajosArpad why would one be faster? B trees are balanced trees. The depth of the tree is the same for both. – Martin Smith Oct 24 '16 at 18:18
-
@MartinSmith the depth is the same, but I doubt the order of siblings would not make a difference – Lajos Arpad Oct 24 '16 at 18:28
-
@MartinSmith, if the order of the siblings has even a slight difference in performance, then running millions of selects would add up, not to mention multi-dimensional joins. – Lajos Arpad Oct 24 '16 at 18:31
-
@MartinSmith, let's consider the difference between a selection having a forward index and a backward index delta. Essentially, if delta is not exactly 0, it is a very small negative or a very small positive, then multiplying it with a large-enough number you get a measurable difference. – Lajos Arpad Oct 24 '16 at 18:34
-
Brilliant insight about the "true single column" index order! Many tend to ignore it. – Murphy Ng Dec 26 '18 at 06:22
9
The sort order matters when you want to retrieve lots of sorted data, not individual records.
Note that (as you are suggesting with your question) the sort order is typically far less significant than what columns you are indexing (the system can read the index in reverse if the order is opposite what it wants). I rarely give index sort order any thought, whereas I agonize over the columns covered by the index.
@Quassnoi provides a great example of when it does matter.
Community
- 1
- 1
Michael Haren
- 105,752
- 40
- 168
- 205