I'm writing an Android word app. My code includes a method that would find all combinations of the string and the substrings of a 7 letter string with a minimum of length 3. Then compare all available combination to every word in the dictionary to find all the valid words. I'm using a recursive method. Here's the code.
// Gets all the permutations of a string.
void permuteString(String beginningString, String endingString) {
if (endingString.length() <= 1){
if((Arrays.binarySearch(mDictionary, beginningString.toLowerCase() + endingString.toLowerCase())) >= 0){
mWordSet.add(beginningString + endingString);
}
}
else
for (int i = 0; i < endingString.length(); i++) {
String newString = endingString.substring(0, i) + endingString.substring(i + 1);
permuteString(beginningString + endingString.charAt(i), newString);
}
}
// Get the combinations of the sub-strings. Minimum 3 letter combinations
void subStrings(String s){
String newString = "";
if(s.length() > 3){
for(int x = 0; x < s.length(); x++){
newString = removeCharAt(x, s);
permuteString("", newString);
subStrings(newString);
}
}
}
The above code runs fine but when I installed it on my Nexus s I realized that it runs a bit too slow. It takes a few seconds to complete. About 3 or 4 seconds which is unacceptable. Now I've played some word games on my phone and they compute all the combinations of a string instantly which makes me believe that my algorithm is not very efficient and it can be improved. Can anyone help?
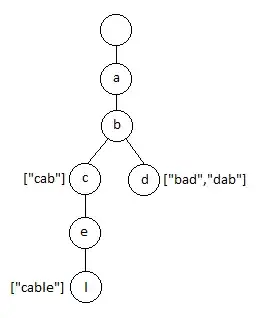
public class TrieNode {
TrieNode a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z;
TrieNode[] children = {a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z};
private ArrayList<String> words = new ArrayList<String>();
public void addWord(String word){
words.add(word);
}
public ArrayList<String> getWords(){
return words;
}
}
public class Trie {
static String myWord;
static String myLetters = "afinnrty";
static char[] myChars;
static Sort sort;
static TrieNode myNode = new TrieNode();
static TrieNode currentNode;
static int y = 0;
static ArrayList<String> availableWords = new ArrayList<String>();
public static void main(String[] args) {
readWords();
getPermutations();
}
public static void getPermutations(){
currentNode = myNode;
for(int x = 0; x < myLetters.length(); x++){
if(currentNode.children[myLetters.charAt(x) - 'a'] != null){
//availableWords.addAll(currentNode.getWords());
currentNode = currentNode.children[myLetters.charAt(x) - 'a'];
System.out.println(currentNode.getWords() + "" + myLetters.charAt(x));
}
}
//System.out.println(availableWords);
}
public static void readWords(){
try {
BufferedReader in = new BufferedReader(new FileReader("c://scrabbledictionary.txt"));
String str;
while ((str = in.readLine()) != null) {
myWord = str;
myChars = str.toCharArray();
sort = new Sort(myChars);
insert(myNode, myChars, 0);
}
in.close();
} catch (IOException e) {
}
}
public static void insert(TrieNode node, char[] myChars, int x){
if(x >= myChars.length){
node.addWord(myWord);
//System.out.println(node.getWords()+""+y);
y++;
return;
}
if(node.children[myChars[x]-'a'] == null){
insert(node.children[myChars[x]-'a'] = new TrieNode(), myChars, x=x+1);
}else{
insert(node.children[myChars[x]-'a'], myChars, x=x+1);
}
}
}