Cascading is a Query API, Query Planner, and Process Scheduler used for defining and executing complex, scale-free, and fault tolerant data processing workflows on a Hadoop cluster.
Cascading is a Query API, Query Planner, and Process Scheduler used for defining and executing complex, scale-free, and fault tolerant data processing workflows on a Hadoop cluster.
Cascading is a thin Java library that sits on top of Hadoop's MapReduce layer and is executed from the command line like any other Hadoop application. It is not a new text based query syntax (like Pig) or another complex system that must be installed on a cluster and maintained (like Hive). Though Cascading is both complimentary to and is a valid alternative to either application.
Cascading lets the developer quickly assemble complex distributed data-processing applications without having to "think" in MapReduce. And to efficiently schedule them based on their dependencies. Obviously simple data processing applications are supported as well, as complex applications tend to start simple.
Cascading is Open Source and dual licensed under the GPL and OEM/Commercial Licenses. OEM/Commercial Licenses and Developer Support can be obtained through Concurrent, Inc.
Cascading has a strong community of users and contributors, see our Cascading modules page for related projects and extensions.
Cascading, extensions, and related libraries are also hosted in the Conjars maven repository maintained by Concurrent, Inc. The repository is open to the public.
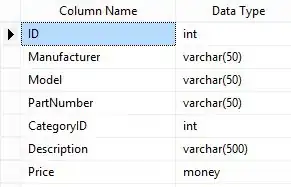
Cascading application-stack overview:
Links: