If I understand your question correctly, then you probably want a density estimate along with the histogram:
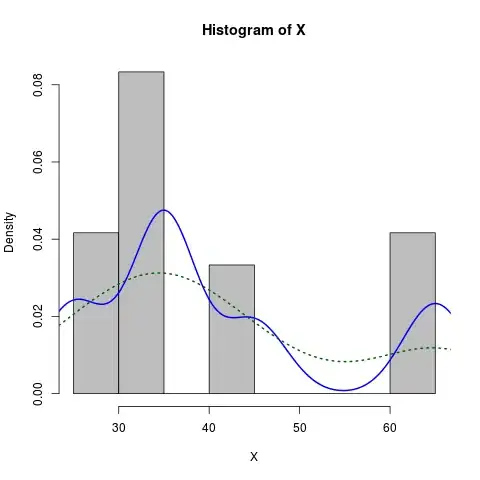
X <- c(rep(65, times=5), rep(25, times=5), rep(35, times=10), rep(45, times=4))
hist(X, prob=TRUE) # prob=TRUE for probabilities not counts
lines(density(X)) # add a density estimate with defaults
lines(density(X, adjust=2), lty="dotted") # add another "smoother" density
Edit a long while later:
Here is a slightly more dressed-up version:
X <- c(rep(65, times=5), rep(25, times=5), rep(35, times=10), rep(45, times=4))
hist(X, prob=TRUE, col="grey")# prob=TRUE for probabilities not counts
lines(density(X), col="blue", lwd=2) # add a density estimate with defaults
lines(density(X, adjust=2), lty="dotted", col="darkgreen", lwd=2)
along with the graph it produces: