To match any whole word you would use the pattern (\w+)
Assuming you are using PCRE or something similar:
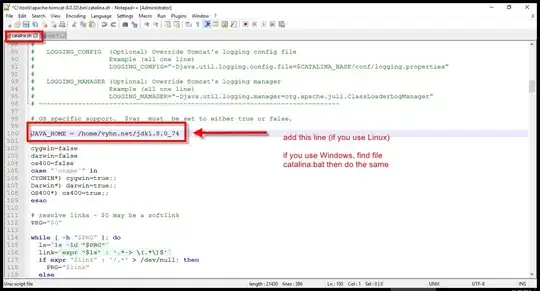
Above screenshot taken from this live example:
https://regex101.com/r/FGheKd/1
Matching any whole word on the commandline with (\w+)
I'll be using the phpsh interactive shell on Ubuntu 12.10 to demonstrate the PCRE regex engine through the method known as preg_match
Start phpsh, put some content into a variable, match on word.
el@apollo:~/foo$ phpsh
php> $content1 = 'badger'
php> $content2 = '1234'
php> $content3 = '$%^&'
php> echo preg_match('(\w+)', $content1);
1
php> echo preg_match('(\w+)', $content2);
1
php> echo preg_match('(\w+)', $content3);
0
The preg_match method used the PCRE engine within the PHP language to analyze variables: $content1, $content2 and $content3 with the (\w)+ pattern.
$content1 and $content2 contain at least one word, $content3 does not.
Match a number of literal words on the commandline with (dart|fart)
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(dart|fart)', $gun1);
1
php> echo preg_match('(dart|fart)', $gun2);
1
php> echo preg_match('(dart|fart)', $gun3);
1
php> echo preg_match('(dart|fart)', $gun4);
0
variables gun1 and gun2 contain the string dart or fart. gun4 does not. However it may be a problem that looking for word fart matches farty. To fix this, enforce word boundaries in regex.
Match literal words on the commandline with word boundaries.
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(\bdart\b|\bfart\b)', $gun1);
1
php> echo preg_match('(\bdart\b|\bfart\b)', $gun2);
1
php> echo preg_match('(\bdart\b|\bfart\b)', $gun3);
0
php> echo preg_match('(\bdart\b|\bfart\b)', $gun4);
0
So it's the same as the previous example except that the word fart with a \b word boundary does not exist in the content: farty.