Say I had some data, for which I want to fit a parametrized model over it. My goal is to find the best value for this model parameter.
I'm doing model selection using a AIC/BIC/MDL type of criterion which rewards models with low error but also penalizes models with high complexity (we're seeking the simplest yet most convincing explanation for this data so to speak, a la Occam's razor).
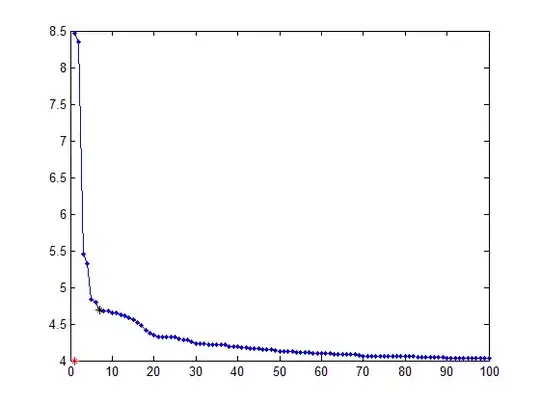
Following the above, this is an example of the sort of things I get for three different criteria (two are to be minimized, and one to be maximized):
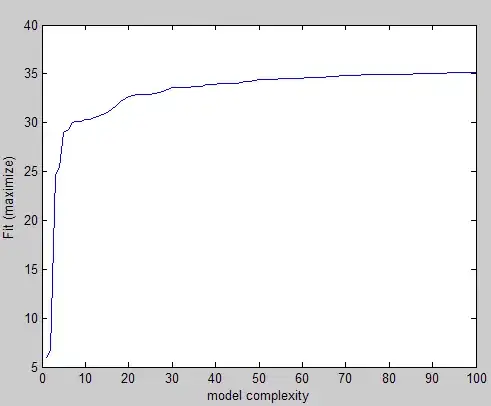
Visually you can easily see the elbow shape and you would pick a value for the parameter somewhere in that region. The problem is that I'm doing do this for large number of experiments and I need a way to find this value without intervention.
My first intuition was to try to draw a line at 45 degrees angle from the corner and keep moving it until it intersect the curve, but that's easier said than done :) Also it can miss the region of interest if the curve is somewhat skewed.
Any thoughts on how to implement this, or better ideas?
Here's the samples needed to reproduce one of the plots above:
curve = [8.4663 8.3457 5.4507 5.3275 4.8305 4.7895 4.6889 4.6833 4.6819 4.6542 4.6501 4.6287 4.6162 4.585 4.5535 4.5134 4.474 4.4089 4.3797 4.3494 4.3268 4.3218 4.3206 4.3206 4.3203 4.2975 4.2864 4.2821 4.2544 4.2288 4.2281 4.2265 4.2226 4.2206 4.2146 4.2144 4.2114 4.1923 4.19 4.1894 4.1785 4.178 4.1694 4.1694 4.1694 4.1556 4.1498 4.1498 4.1357 4.1222 4.1222 4.1217 4.1192 4.1178 4.1139 4.1135 4.1125 4.1035 4.1025 4.1023 4.0971 4.0969 4.0915 4.0915 4.0914 4.0836 4.0804 4.0803 4.0722 4.065 4.065 4.0649 4.0644 4.0637 4.0616 4.0616 4.061 4.0572 4.0563 4.056 4.0545 4.0545 4.0522 4.0519 4.0514 4.0484 4.0467 4.0463 4.0422 4.0392 4.0388 4.0385 4.0385 4.0383 4.038 4.0379 4.0375 4.0364 4.0353 4.0344];
plot(1:100, curve)
EDIT
I accepted the solution given by Jonas. Basically, for each point p on the curve, we find the one with the maximum distance d given by: